本篇文章基于qemu2.6.0,Linux3.10.0内核,x86体系结构。Qemu与KVM同步脏页位图主要分为Qemu与KVM两部分,我们先来看看Qemu部分。
Qemu部分
主要内容:Qemu将KVM返回的位图设置到自己的ram_list->dirty_memory->blocks中的map位图
address_space_sync_dirty_bitmap
主要调用了kvm_log_sync将kvm内核中的位图(kvm_memory_slot.dirty_bitmap)同步到qemu。本函数在热迁移过程中被migration_bitmap_sync函数调用。
void address_space_sync_dirty_bitmap(AddressSpace *as)
{
FlatView *view;
FlatRange *fr;
view = address_space_get_flatview(as);
/* 对每一个flat range调用memory_listeners里的所有log_sync。由于只有kvm_memory_listener中
* log_sync是初始化了的,所以相当于对每一个flat range调用kvm_memory_listener中log_sync
*/
FOR_EACH_FLAT_RANGE(fr, view) {
//这里调用kvm_log_sync
MEMORY_LISTENER_UPDATE_REGION(fr, as, Forward, log_sync);
}
flatview_unref(view);
}
kvm_log_sync
//这是下面kvm_log_sync函数的第二个参数section,一个FlatRange转换成一个MemoryRegionSection
(&(MemoryRegionSection) { \
.mr = (fr)->mr, \
.address_space = (as), \
.offset_within_region = (fr)->offset_in_region, \
.size = (fr)->addr.size, \
.offset_within_address_space = int128_get64((fr)->addr.start), \//起始物理地址
.readonly = (fr)->readonly, \
})
static void kvm_log_sync(MemoryListener *listener,
MemoryRegionSection *section)
{
//这里返回listener所属的KVMMemoryListener。每个MemoryListener都包含在一个KVMMemoryListener
//大家或许有疑问:这里返回KVMMemoryListener干嘛?KVMMemoryListener串起了整个VM物理地址空间对应的
//KVMSlot。所以下面kvm_physical_sync_dirty_bitmap的section就可以通过kml找到对应的KVMSlot
KVMMemoryListener *kml = container_of(listener, KVMMemoryListener, listener);
int r;
r = kvm_physical_sync_dirty_bitmap(kml, section);
if (r < 0) {
abort();
}
}
static int kvm_physical_sync_dirty_bitmap(KVMMemoryListener *kml,
MemoryRegionSection *section)
{
KVMState *s = kvm_state;
unsigned long size, allocated_size = 0;
struct kvm_dirty_log d = {};
KVMSlot *mem;
int ret = 0;
//这里计算出section对应的物理地址区间
hwaddr start_addr = section->offset_within_address_space;
hwaddr end_addr = start_addr + int128_get64(section->size);
d.dirty_bitmap = NULL;
while (start_addr < end_addr) {
//根据物理地址区间找到对应的KVMSlot
mem = kvm_lookup_overlapping_slot(kml, start_addr, end_addr);
......
//把物理地址区间大小转换成 页框数对应位图的字节数。一个页框对应位图的一个位
//所以这里除8就是要分配位图的字节数
size = ALIGN(((mem->memory_size) >> TARGET_PAGE_BITS),
/*HOST_LONG_BITS*/ 64) / 8;
if (!d.dirty_bitmap) {
d.dirty_bitmap = g_malloc(size);//先给位图分配空间
} else if (size > allocated_size) {
d.dirty_bitmap = g_realloc(d.dirty_bitmap, size);
}
allocated_size = size;
//设置为全0,d.dirty_bitmap就是等下要传递给内核的参数,让内核将其脏页位图同步到d.dirty_bitmap
memset(d.dirty_bitmap, 0, allocated_size);
//把地址空间id 和 KVMSlot编号传递给内核,以便其查找到对应的 kvm_memory_slot
d.slot = mem->slot | (kml->as_id << 16);
//主要完成将内核slot的脏页位图设置到d.dirty_bitmap。且重置内核slot的脏页位图
//和清除EPT页表项的脏标志。KVM使用 kvm_vm_ioctl_get_dirty_log 完成以上操作
//具体过程请看 内核部分
if (kvm_vm_ioctl(s, KVM_GET_DIRTY_LOG, &d) == -1) {
DPRINTF("ioctl failed %d\n", errno);
ret = -1;
break;
}
//更新Qemu的脏页位图。qemu的脏页位图存放于 ram_list.dirty_memory
kvm_get_dirty_pages_log_range(section, d.dirty_bitmap);
start_addr = mem->start_addr + mem->memory_size;
}
g_free(d.dirty_bitmap);//释放掉临时位图,由于已经设置到ram_list.dirty_memory
return ret;
}
kvm_get_dirty_pages_log_range
更新Qemu的脏页位图。在看具体操作前,我们先看看整体的qemu中ram_list.dirty_memory脏页位图结构:
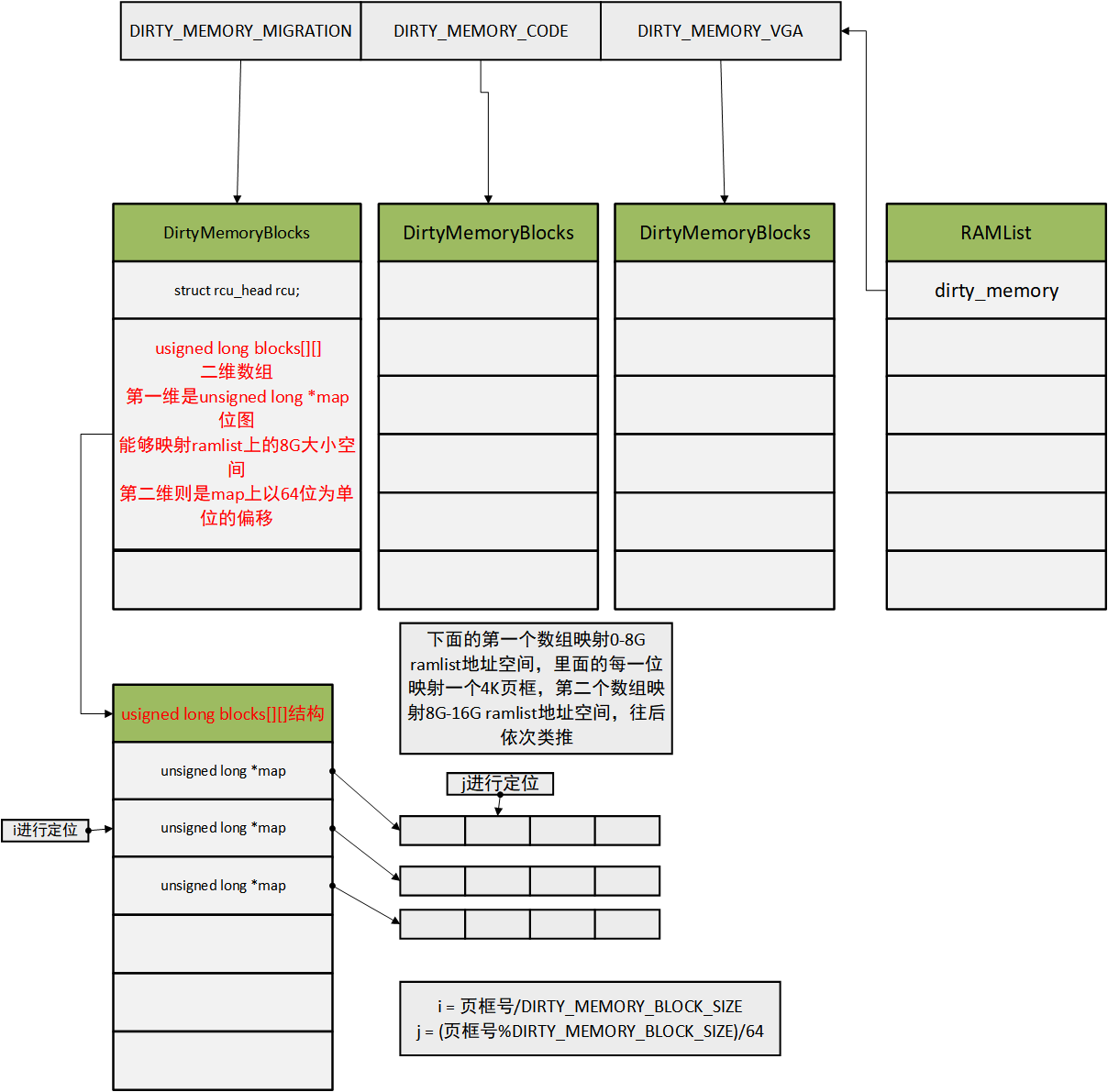
后面的代码稍微有些复杂,可以结合这个图看,相信会轻松许多。
/* get kvm's dirty pages bitmap and update qemu's */
static int kvm_get_dirty_pages_log_range(MemoryRegionSection *section,
unsigned long *bitmap)
{
//在整个ram_list上的起始地址
ram_addr_t start = section->offset_within_region +
memory_region_get_ram_addr(section->mr);
//section拥有的页框数
ram_addr_t pages = int128_get64(section->size) / getpagesize();
//这里会把bitmap设置到上图中map指针指向的位图中
cpu_physical_memory_set_dirty_lebitmap(bitmap, start, pages);
return 0;
}
既然要设置到blocks中的map位图,那总得知道要设置的起始偏移。这里要讨论两种情况:1、section在ram_list上的起始物理页框号是64对齐的(也就是能被64整除)2、section在ram_list上的起始物理页框号不是64对齐的。这里我们先讨论比较简单的第一种情况:
64位对齐的情况下

static inline void cpu_physical_memory_set_dirty_lebitmap(unsigned long *bitmap,
ram_addr_t start,
ram_addr_t pages)
{
unsigned long i, j;
unsigned long page_number, c;
hwaddr addr;
ram_addr_t ram_addr;
//以64位为单位计算的bitmap的长度
unsigned long len = (pages + HOST_LONG_BITS - 1) / HOST_LONG_BITS;
unsigned long hpratio = getpagesize() / TARGET_PAGE_SIZE;
//利用在ramlist中的起始页框号/64 计算出 map位图的索引
unsigned long page = BIT_WORD(start >> TARGET_PAGE_BITS);
/* 如果section的起始页框号是64对齐的 */
if ((((page * BITS_PER_LONG) << TARGET_PAGE_BITS) == start) &&
(hpratio == 1)) {
unsigned long **blocks[DIRTY_MEMORY_NUM];
unsigned long idx;
unsigned long offset;
long k;
long nr = BITS_TO_LONGS(pages);//以64位为单位计算bitmap的长度
//这里的idx和offset就是前面第一个图上的i和j
idx = (start >> TARGET_PAGE_BITS) / DIRTY_MEMORY_BLOCK_SIZE;
offset = BIT_WORD((start >> TARGET_PAGE_BITS) %
DIRTY_MEMORY_BLOCK_SIZE);
rcu_read_lock();
for (i = 0; i < DIRTY_MEMORY_NUM; i++) {
blocks[i] = atomic_rcu_read(&ram_list.dirty_memory[i])->blocks;
}
for (k = 0; k < nr; k++) {
if (bitmap[k]) {//存在脏页
unsigned long temp = leul_to_cpu(bitmap[k]);
//直接设置到map的offset对应项中
atomic_or(&blocks[DIRTY_MEMORY_MIGRATION][idx][offset], temp);
atomic_or(&blocks[DIRTY_MEMORY_VGA][idx][offset], temp);
if (tcg_enabled()) {
atomic_or(&blocks[DIRTY_MEMORY_CODE][idx][offset], temp);
}
}
//offset对应64bit的第一位对应页框在ramlist上的地址已经超过8G
if (++offset >= BITS_TO_LONGS(DIRTY_MEMORY_BLOCK_SIZE)) {
offset = 0;
idx++;//则换到blocks的下一个map位图
}
}
rcu_read_unlock();
xen_modified_memory(start, pages << TARGET_PAGE_BITS);
} else {
//后面再说明非对齐的情况
}
}
在对齐的情况下,此算法还是很简单的,直接把bitmap一项一项设置到map位图即可。接下来看未对齐的情况:
64位未对齐的情况下

在这种情况下只能把bitmap的每一项取出来,依次设置里面的每一个1位到map位图。请看代码:
static inline void cpu_physical_memory_set_dirty_lebitmap(unsigned long *bitmap,
ram_addr_t start,
ram_addr_t pages)
{
unsigned long i, j;
unsigned long page_number, c;
hwaddr addr;
ram_addr_t ram_addr;
//以64位为单位计算的bitmap的长度
unsigned long len = (pages + HOST_LONG_BITS - 1) / HOST_LONG_BITS;
unsigned long hpratio = getpagesize() / TARGET_PAGE_SIZE;
......
/* start address is aligned at the start of a word? */
if ((((page * BITS_PER_LONG) << TARGET_PAGE_BITS) == start) &&
......//对齐的情况下
} else {
uint8_t clients = tcg_enabled() ? DIRTY_CLIENTS_ALL : DIRTY_CLIENTS_NOCODE;
/*
* bitmap-traveling is faster than memory-traveling (for addr...)
* especially when most of the memory is not dirty.
*/
for (i = 0; i < len; i++) {
if (bitmap[i] != 0) {//这个64位区间存在脏页
c = leul_to_cpu(bitmap[i]);
do {
j = ctzl(c);//返回第一个1的位置,方便后面计算page_number
c &= ~(1ul << j);//把c中的第一个1清空
page_number = (i * HOST_LONG_BITS + j) * hpratio;
addr = page_number * TARGET_PAGE_SIZE;
ram_addr = start + addr;//计算出bitmap第一个脏页框在ramlist中的地址
//只设置一个脏页的脏页位
cpu_physical_memory_set_dirty_range(ram_addr,
TARGET_PAGE_SIZE * hpratio, clients);
} while (c != 0);//整个循环能够设置完64位的脏页位
}
}//将bitmap整个完整的设置到qemu的blocks位图中
}
}
接下来我们看看如何设置一个脏页的脏页位。start是脏页的ramlist上的起始地址,length为4K。
static inline void cpu_physical_memory_set_dirty_range(ram_addr_t start,
ram_addr_t length,
uint8_t mask)
{
DirtyMemoryBlocks *blocks[DIRTY_MEMORY_NUM];
unsigned long end, page;
unsigned long idx, offset, base;
int i;
......
//结束页框号
end = TARGET_PAGE_ALIGN(start + length) >> TARGET_PAGE_BITS;
//起始脏页页框号
page = start >> TARGET_PAGE_BITS;
rcu_read_lock();
for (i = 0; i < DIRTY_MEMORY_NUM; i++) {
blocks[i] = atomic_rcu_read(&ram_list.dirty_memory[i]);
}
//page页框号对应 页框地址 小于8G的情况下,idx = 0,offset = page
//(这里的offset是不能拿去直接索引map位图的,因为这里的offset是页框号)
idx = page / DIRTY_MEMORY_BLOCK_SIZE;
offset = page % DIRTY_MEMORY_BLOCK_SIZE;
base = page - offset;//base为0
while (page < end) {//这个循环只执行一次
unsigned long next = MIN(end, base + DIRTY_MEMORY_BLOCK_SIZE);
if (likely(mask & (1 << DIRTY_MEMORY_MIGRATION))) {
bitmap_set_atomic(blocks[DIRTY_MEMORY_MIGRATION]->blocks[idx],
offset, next - page);//设置脏页位
}
if (unlikely(mask & (1 << DIRTY_MEMORY_VGA))) {
bitmap_set_atomic(blocks[DIRTY_MEMORY_VGA]->blocks[idx],
offset, next - page);
}
if (unlikely(mask & (1 << DIRTY_MEMORY_CODE))) {
bitmap_set_atomic(blocks[DIRTY_MEMORY_CODE]->blocks[idx],
offset, next - page);
}
......
}
......
}
void bitmap_set_atomic(unsigned long *map, long start, long nr)
{
//把页框号start转换为map的索引,p指向的unsigned long中的某一位就是我们要设置的位。
unsigned long *p = map + BIT_WORD(start);
const long size = start + nr;
int bits_to_set = BITS_PER_LONG - (start % BITS_PER_LONG);
//根据页框号start算出在unsigned long 64位中的偏移值
//mask_to_set = 1<<偏移值
unsigned long mask_to_set = BITMAP_FIRST_WORD_MASK(start);
/* First word */
if (nr - bits_to_set > 0) {
atomic_or(p, mask_to_set);//使用或操作将其设置为1
nr -= bits_to_set;
bits_to_set = BITS_PER_LONG;
mask_to_set = ~0UL;
p++;
}
......
}
以上是Qemu设置 内核传递的脏页位图分析过程。接下来我们看看内核如何传递脏页位图给Qemu。
内核部分
内核部分主要完成传递脏页位图给Qemu、清空脏页位图、清除脏页对应EPT页表项的脏标志。
kvm_vm_ioctl(KVM_GET_DIRTY_LOG)
由kvm_log_sync->kvm_physical_sync_dirty_bitmap进行调用。在看下面的代码时,可以回到这里查看总体结构图,以防迷失:
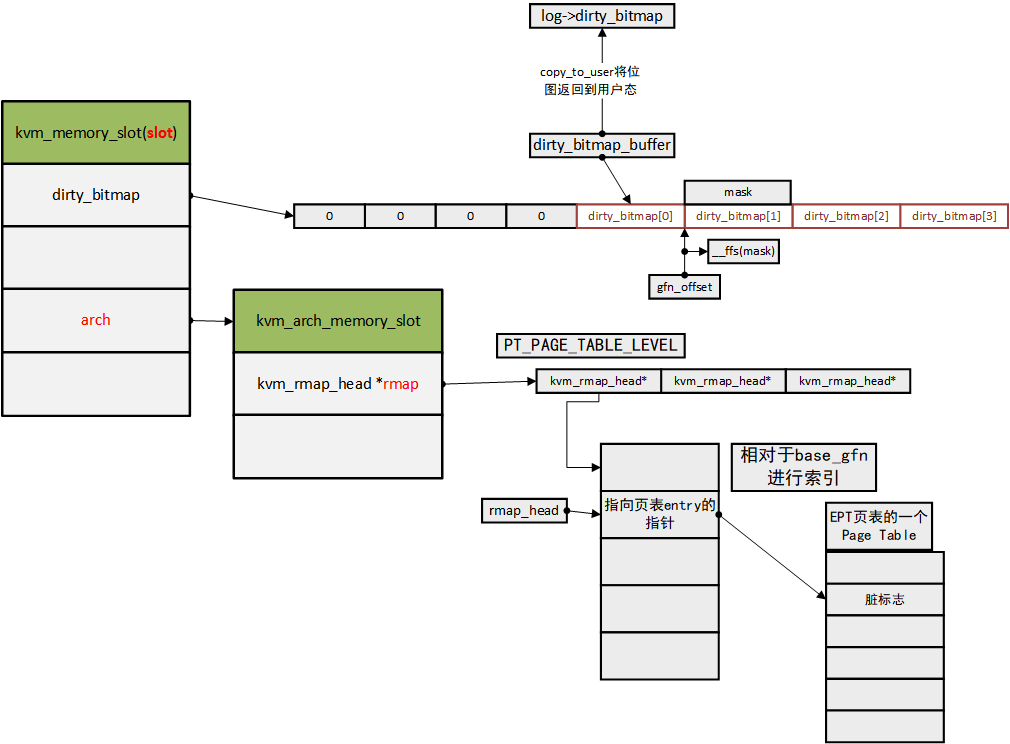
接下来开始看代码:
kvm_vm_ioctl(s, KVM_GET_DIRTY_LOG, &d)
//内核
static long kvm_vm_ioctl(struct file *filp,unsigned int ioctl, unsigned long arg)
{
struct kvm *kvm = filp->private_data;
......
case KVM_GET_DIRTY_LOG: {
struct kvm_dirty_log log;
r = -EFAULT;
//至于这里为什么要用copy_from_user而不用memcpy
//请参考https://blog.csdn.net/ce123_zhouwei/article/details/8454226
if (copy_from_user(&log, argp, sizeof(log)))//成功执行拷贝操作 返回0
goto out;
r = kvm_vm_ioctl_get_dirty_log(kvm, &log);
break;
}
......
return r;
}
int kvm_vm_ioctl_get_dirty_log(struct kvm *kvm, struct kvm_dirty_log *log)
{
bool is_dirty = false;
int r;
mutex_lock(&kvm->slots_lock);
......
r = kvm_get_dirty_log_protect(kvm, log, &is_dirty);
......
mutex_unlock(&kvm->slots_lock);
return r;
}
int kvm_get_dirty_log_protect(struct kvm *kvm,
struct kvm_dirty_log *log, bool *is_dirty)
{
struct kvm_memslots *slots;
struct kvm_memory_slot *memslot;
int r, i, as_id, id;
unsigned long n;
unsigned long *dirty_bitmap;
unsigned long *dirty_bitmap_buffer;
r = -EINVAL;
as_id = log->slot >> 16;//取出用户态传递进来的地址空间id
id = (u16)log->slot;//以及slot id
if (as_id >= KVM_ADDRESS_SPACE_NUM || id >= KVM_USER_MEM_SLOTS)
goto out;
slots = __kvm_memslots(kvm, as_id);//返回地址空间对应的kvm_memslots
//以slots.id_to_index[slot_id]的值为index,找到slots.memslots[index]对应的kvm_memory_slot
memslot = id_to_memslot(slots, id);
dirty_bitmap = memslot->dirty_bitmap;
//计算需要多少字节的位图,才能映射完当前的kvm_memory_slot
n = kvm_dirty_bitmap_bytes(memslot);
//等下会将dirty_bitmap位图复制到dirty_bitmap_buffer开始的位置
dirty_bitmap_buffer = dirty_bitmap + n / sizeof(long);
//初始化dirty_bitmap_buffer开始的n个字节为0
//dirty_bitmap_buffer主要是用来保存当前的dirty_bitmap,后面会设置到log->dirty_bitmap返回给Qemu
memset(dirty_bitmap_buffer, 0, n);
spin_lock(&kvm->mmu_lock);
*is_dirty = false;
for (i = 0; i < n / sizeof(long); i++) {//n是8字节对齐的
unsigned long mask;
gfn_t offset;
if (!dirty_bitmap[i])//非脏页直接跳过
continue;
*is_dirty = true;
mask = xchg(&dirty_bitmap[i], 0);//把dirty_bitmap对应的项置0,且置换出原来的值
dirty_bitmap_buffer[i] = mask;//设置对应dirty_bitmap_buffer
//接下来开始清除EPT页表项的脏标志
if (mask) {
//脏页位图上的偏移
offset = i * BITS_PER_LONG;
//由于mask里有一些可能还是0,所以需要传入mask避免不需要的 清除脏标志操作
//从offset开始的64bit,都需要检查
kvm_arch_mmu_enable_log_dirty_pt_masked(kvm, memslot,offset, mask);
}
}
spin_unlock(&kvm->mmu_lock);
//这里log对象虽然在内核栈中,但是由于前面掉用了copy_from_user
//所以这里的log->dirty_bitmap指针是指向用户态的
if (copy_to_user(log->dirty_bitmap, dirty_bitmap_buffer, n))//把获取到的位图。拷贝到用户态
goto out;
r = 0;
out:
return r;
}
清除脏标志的具体过程:
void kvm_arch_mmu_enable_log_dirty_pt_masked(struct kvm *kvm,
struct kvm_memory_slot *slot,//要清除脏标志的kvm_memory_slot
gfn_t gfn_offset, //要清除脏标志的 起始页框号(以slot的起始页框号为基准)
unsigned long mask)//标志哪些页框是要清除脏标志,哪些不需要
{
//对于x86体系结构下该函数指针为 vmx_enable_log_dirty_pt_masked
if (kvm_x86_ops->enable_log_dirty_pt_masked)
kvm_x86_ops->enable_log_dirty_pt_masked(kvm, slot, gfn_offset,mask);
else
......
}
static void vmx_enable_log_dirty_pt_masked(struct kvm *kvm,
struct kvm_memory_slot *memslot,
gfn_t offset, unsigned long mask)
{
kvm_mmu_clear_dirty_pt_masked(kvm, memslot, offset, mask);
}
void kvm_mmu_clear_dirty_pt_masked(struct kvm *kvm,
struct kvm_memory_slot *slot,
gfn_t gfn_offset, unsigned long mask)
{
struct kvm_rmap_head *rmap_head;
while (mask) {
//slot->base_gfn + gfn_offset + __ffs(mask) 计算出要清除脏标志的物理页框号,假设为K
//通过slot->arch.rmap[PT_PAGE_TABLE_LEVEL] + (K - slot->base_gfn)得到rmap_head
rmap_head = __gfn_to_rmap(slot->base_gfn + gfn_offset + __ffs(mask),
PT_PAGE_TABLE_LEVEL, slot);
//把rmap_head对应的EPT页表项脏标志置0
__rmap_clear_dirty(kvm, rmap_head);
/* clear the first set bit */
mask &= mask - 1;
}
}
到此为止清除EPT页表项脏标志和返回bitmap到Qemu的流程分析完毕。
总结
最后我们总结一下整个脏页同步过程:
1、KVM将自身脏页通过qemu传递的参数传递给QEMU,且清空脏页位图,清除脏页对应EPT页表项的脏标志。
2、Qemu将KVM返回的位图设置到自己的ram_list->dirty_memory->blocks中的map位图。注意这里设置了三份blocks位图。DIRTY_MEMORY_MIGRATION、DIRTY_MEMORY_VGA、DIRTY_MEMORY_CODE。这三个位图是一模一样的,至于为什么要设置三个一模一样的位图,应该是他们分别用在不同的地方。这里只关注DIRTY_MEMORY_MIGRATION就行(我们更关注热迁移)。
文章中有哪些错误,或者不太容易理解的地方,欢迎在下方指正,大家共同学习进步。谢谢!